Download query results in a TAB-deliminated format
In this tutorial we will learn how to download query results in a delimited text file, more precicely in a TAB-delimited text file, out of CQPweb. See Data and data formats for more information on formats for data sets.
Things you have to know about CQP
- A CQP corpus is based on an index
- All words in a corpus are numbered beginning from “0”. We refer to this number as corpus position.
- In the internal representation each hit is represented by so-called
anchors. The mainanchorsare the corpus position of the first and the last word in the hit. - Other
anchorsare the so-calledtargetandkeyword. Both of which are optional and have to be specifically defined for a query (we will ignore them in this tutorial).
In order to understand the concept better, let’s have a look an example. The diagram below shows the beginning of a corpus. In the first column you see the corpus position and in the second column the words.
0 Alice
1 's
2 adventures
3 in
4 wonderland
5 Down
6 the
7 Rabbit-Hole
8 ALICE
9 was
10 beginning
11 to
12 get
13 very
14 tired
15 of
16 sitting
17 by
18 her
19 sister
20 onLet’s assume we looked for noun phrases in this subset of the corpus and we get the following results.
Alice 's adventures
wonderland
the Rabbit-Hole
ALICE
her sisterCQP represents these results in terms of corpus positions, i.e., the first token (refered to as match) and the last token (refered to as matchend) in the result item. These positions are also refered to as anchor positions. Thus, the internal represenation of the query results is:
match matchend
0 2
4 4
6 7
8 8
18 19Attention: each hit is represented by two corpus positions (the anchors: match and matchend) not matter of the length of the string. For hits consisting solely of one word match and matchend are the same, e.g. for the ALICE in our example. These anchor positions play an important role if we want to download results in a TAB-delimited format.
How to download results
- choose
Downloadfrom the Menu in the upper right corner of the concordance window and click onGo. - you are now on the window for downloading concordance lines
- scroll all the way down on the page and click on
Download query as plain-text tabulation - You will see the following window
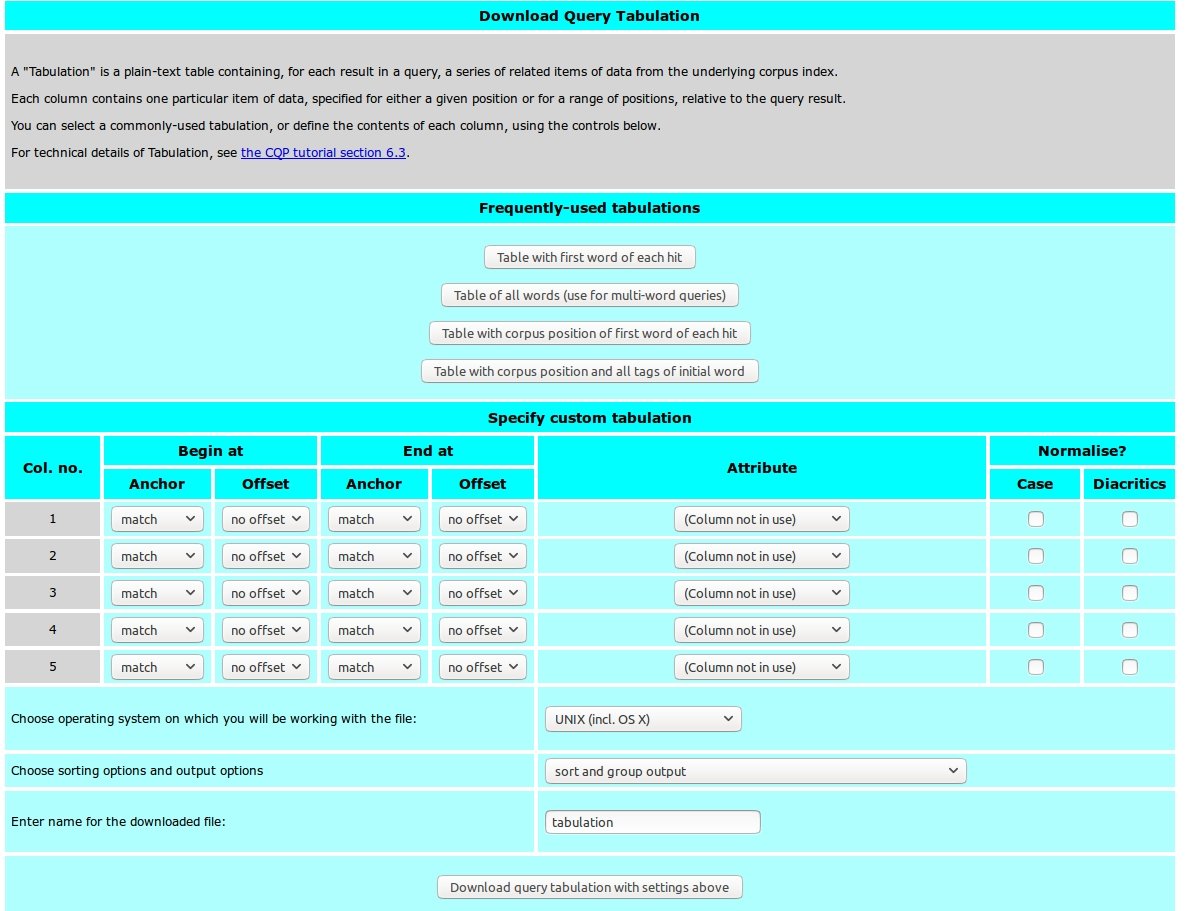
Under Frequently-used tabulations you can find a number of preinstalled tabulation commands.
Specify a custom tabulation
We can principally download any attribute annotated in the Corpus for our match string. With the form below Specify custom tabulation we define the which values or features we want to extract for which tokens.
Lets have a look at the form below Specify custom tabulation in more detail:
Col.no.: column in the download table - each column stands for a particular valueBegin atadEnd at: specifies the token(s) for which we want to extract the valuesAnchor: corpus position anchor (e.g.match,matchend)Offset: offset for theanchorAttribute: specifies the value
A simple example
- Phenomena: distribution of full verbs and their parts-of-speech across registers in the Brown corpus
- Query:
[pos="VV.*"]. - Features/Values: verb lemma, part-of-speech of verb, register
Specifications for the download table:
- column(s): three columns, one for each value
- token(s):
matchwith no offset - corpus attribute(s):
lemma,pos,text_reg - output format:
simple tabulate output
The Specify custom tabulation form looks like this: 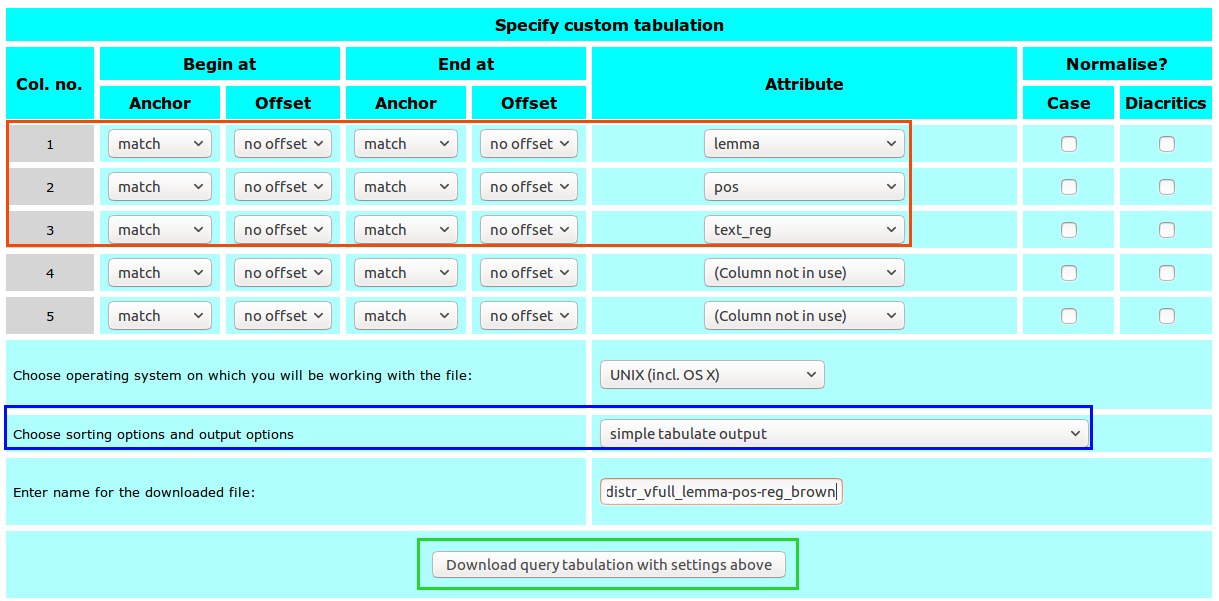
The result should look like this. We have three columns (one for each variable)
- column 1: verb lemma
- column 2: pos of verb
- column 3: register
and one row for each instance in the corpus.
This format is well suited as input format for statistical analysis programs such as R.
Principally, we have the following output format options:
simple tabulate outputas described abovesort and group outputwhich calculate frequencies for each combination of attributessort and group output, display as matrix, which presents the results in a matrix (useful only for two variables). Column 1 will be the matrix rows, column 2 the matrix columns. In the example here, we used the following parameters:- column 1 (matrix rows): verb lemma
- column 2 (matrix columns): register
Example with pattern of more than one token
- Phenomena: distribution of preposition in complex noun phrases (N-prep-N) over time in the RSC
- Query:
[pos="N.*"] [pos="IN"] [pos="N.*"] - Features/Values: preposition lemma, time period
Pay attention, the preposition is neither at the beginning (match) nor at the end (matchend) of the pattern. In order to extract the lemma of the preposition we need to specify the corpus position relative to one of these anchors. This is done with the so-called offset. A positive offset referst to the right or to what follows the anchor, a negative offset refers to the left or to what precedes the anchor. As the preposition is one position to the right of match (match[+1]) and one position left of matchend (matchend[-1]), we could use either anchor.
The Specify custom tabulation form using match[+1] looks like this
{kind=link}
Pay attention, we extract text_decade at the position match (without offset).
The result of the download should look like this