Data extraction and data formats
The result of a corpus linguistic study is usually a so-called data set. Such a data set contains information about a particular linguistic phenomeno extracted from a particular corpus.
In this tutorial we will learn how to create such data sets using the online search tool CQPweb.
A few words about data sets
A data set
- is a collection of data/information about a particular phenomenon
- typically consists of observations, variables (also attribute) and values of the variables.
In a corpus linguistic study observations are usually associated with instances in a given corpus, and variables are also often called features.
Datasets are structured to make relations between elements explicit. Most commonly a dataset is structured as follows:
- each observation is on a separate line
- each variable is a column
- each cell holds a value
Wickham (2014) calls this a tidy dataset, which is easy to manipulate, model and visualize.
The datasets are usually stored in delimited plain text format. Typical deliminators are commas (CSV), semicolons or TABs. For datasets including language material it is most common to use a TAB-delimited format. While most other characters (commas, semicolon, white space, …) may be part of a linguistic signal, TABs are not, thus they do not conflict with potential elements of a value.
Example study
Let us assume we are interested in the distribution of content verbs and their parts-of-speech across registers in the Brown corpus. We could formularize our study as follows:
- research question: distribution of content verbs and their parts-of-speech across registers in the Brown corpus
- observation: each instance of a content verb in the Brown corpus
- variables/features: lemma/word form of verb, part-of-speech tag of verb, register
The corresponding tidy dataset should look like this: distr_vfull_lemma-pos-reg_brown.txt.
In the following you will now learn how to create this data set.
Extracting data from a corpus in CQPweb
Things you have to know about CQP
- A CQP corpus is based on an index.
- All words in a corpus are numbered beginning from “0”. We refer to these numbers as corpus positions.
- Each instance of a query result is called a
match. - In the internal representation each match is represented by corpus positions, the so-called
anchors.
- The main anchors of a match are the corpus positions marking the beginning and the end of a query result.
- They are called
matchfor the beginning of the match andmatchendfor the end of the match. - Other anchors are
targetandkeyword. They are both optional and have to be specifically defined in a query (we will ignore them for the time being).
In order to understand the concept better, let’s have a look an example. The diagram below shows the beginning of a corpus. In the first column you see the corpus position and in the second column the words.
0 Alice
1 's
2 adventures
3 in
4 wonderland
5 Down
6 the
7 Rabbit-Hole
8 ALICE
9 was
10 beginning
11 to
12 get
13 very
14 tired
15 of
16 sitting
17 by
18 her
19 sister
20 onLet’s assume we looked for noun phrases in this subset of the corpus and we get the following results.
Alice 's adventures
wonderland
the Rabbit-Hole
ALICE
her sisterCQP represents these results in terms of corpus positions, i.e., the corpus position of the first token (refered to as match) and the last token (refered to as matchend). Thus, the internal represenation the query result look like this:
0 2
4 4
6 7
8 8
18 19Attention: each hit is represented by two corpus positions (for match and matchend) no matter of the length of the string. For results consisting solely of one word match and matchend are the same (e.g. in the case of wonderland and ALICE; line 2 and line 4). These anchor positions play an important role if we want to extract a data set for a corpus in CQPweb.
Corpus Search
The first thing we have to do in order to extract data is obviously to run a query.
Let us return to our example study of content verbs and their parts-of-speech across registers in the Brown corpus:
The query is rather simple, searching for every occurence of a content verb:
- query:
[pos="VV.*"].
After executing the query in CQPweb, we get concordances showing each instance of a content verb (in this case in the Brown corpus) in context.
See Introduction to CQPweb: Corpus Search for more information on how to execute queries in CQPweb.
Downloading results
In order to download the results of a query as a data set:
- choose
Downloadfrom the Menu in the upper right corner of the concordance window and click onGo. - you are now on the window for downloading concordance lines
- scroll all the way down on the page and click on
Download query as plain-text tabulation - You will see the following window
Under Frequently-used tabulations you can find a number of preinstalled tabulation commands.
Specify a custom tabulation
If none of the preinstalled tabulation commands extracts the features we need (as is the case in our example), we have to specify a custom tabulation.
Lets have a look at the form Specify custom tabulation in more detail:
Col.no.: column in the download table - each column represents a variable/featureBegin atadEnd at: specifies the begin and end corpus positions of the token(s) for which we want to extract the variable/featuresAnchor: anchor for corpus position (e.g.match,matchend)Offset: offset for theanchor- with the offset, we can specify a corpus position relative to one of the anchorsAttribute: attribute of the variable/feature
Extract the data set
To recall the parameters of our example study:
- research question: distribution of full verbs and their parts-of-speech across registers in the Brown corpus
- query:
[pos="VV.*"]. - observation: each instance of a full verb in the Brown corpus
- features/variables: verb lemma, part-of-speech of verb, register
Parameters for the custom tabulation:
- three columns (one for each variable, order does not matter)
- column 1: verb lemma; attribute:
lemma; anchor:match - column 2: pos of verb; attribute:
pos; anchor:match - column 3: register; attribute:
text_reg; anchor:match
- column 1: verb lemma; attribute:
- output format:
simple tabulate output
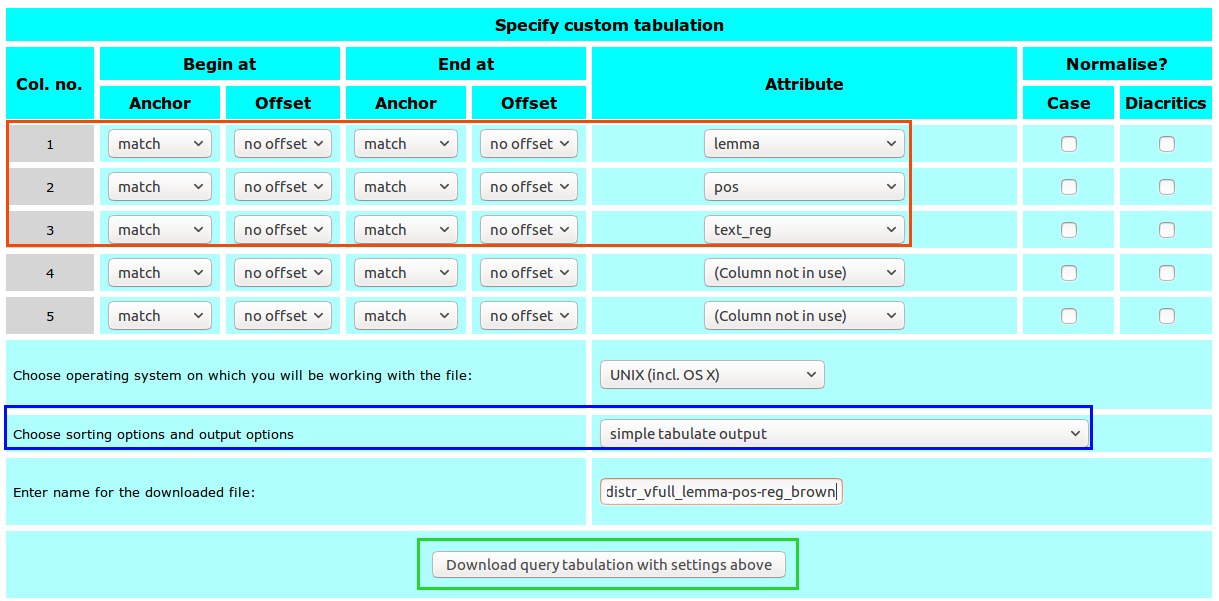
Once you have specified all parameters in the custom tabulation form you can download the results by clicking on Download query tabulation with settings above.
Save the file under data/distr_vfull_lemma-pos-reg_brown.txt in the course directory. If you haven’t filled in the name for the download file before, you can specify the name of the file now.
Result of the download: distr_vfull_lemma-pos-reg_brown.txt.
We now have created a tidy data set, which is most flexible with regard to manipulation, modeling and vizualization.
However, principally, we have the following output format options:
simple tabulate outputas described abovesort and group outputwhich calculate frequencies for each combination of featuressort and group output, display as matrix, which presents the results in a matrix (two variables only).
Column 1 will be the matrix rows, column 2 the matrix columns. In the example here, we used the following variables:- column 1 (matrix rows): verb lemma
- column 2 (matrix columns): register
Extract data for query patterns with more than one token
The same data extraction methods can be used for queries including patterns with more than one token.
Extract a sequence of tokens
- research question: distribution of complex noun phrases (N-prep-N) over time in the RSC
- query:
[pos="N.*"] [pos="IN"] [pos="N.*"] - observations: all complex noun phrases (N-prep-N) in the RSC
- features/variables: complex noun phrases, time period
Pay attention:
- for the complex noun phrase
- we use different anchors for beginning and end as it is a sequence of tokens
- we use
wordinstead of lemma for the complex noun phrase and normalize it forcase(to avoid differences due to capitalization of words)
- for the time period,
- we use
text_period(50-year periods) - we us the same anchor for beginning and end, as we need the time period only once!
- we use
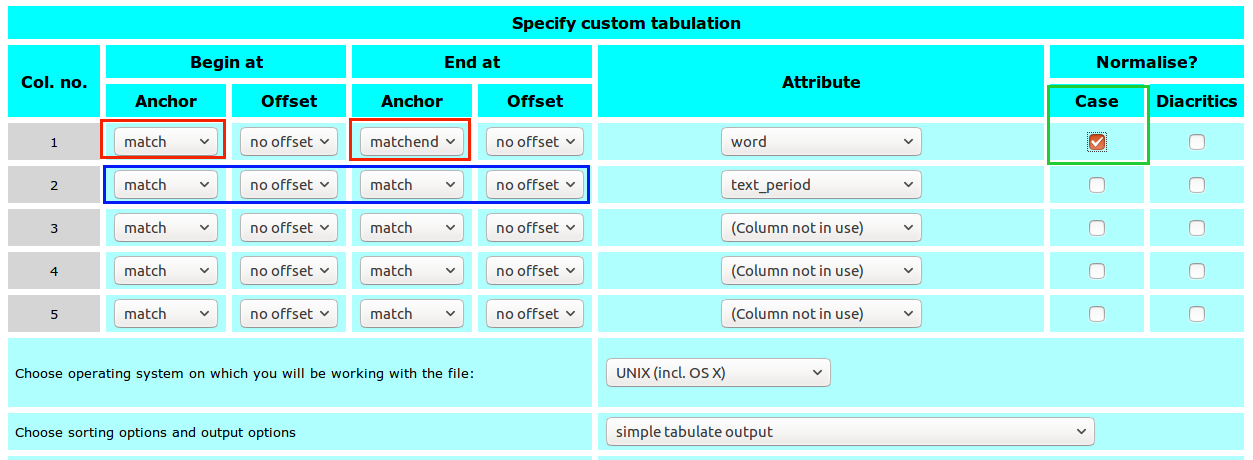
Save the results under data/distr_n-prep-n_np-word-period_rsc.txt in your course directory.
Result of the download: distr_n-prep-n_np-word-period_rsc.txt
Extract a single token out of a sequence
- research question: distribution of preposition in complex noun phrases (N-prep-N) over time in the RSC
- query:
[pos="N.*"] [pos="IN"] [pos="N.*"] - observations: all prepositions in complex noun phrases (N-prep-N) in the RSC
- features/variables: lemma of preposition, time period
Pay attention:
- for the prepositon
- we use
lemmainstead of word - the preposition is neither at the beginning (
match) nor at the end (matchend) of the matching pattern. Thus, we have to specify the corpus position of the preposition relative to one of the anchors. This is done with the so-calledoffset. In our case, we can use eithermatchormatchendas the preposition is one position right of (following) match (match[+1]) and one position left of (preceeding) matchend (matchend[-1]). - in the example below, we use
match[+1]
- we use
- for the time period
- we use
text_decadeinstead oftext_period - we do not use the offset for
text_decadeas it is the same for the whole pattern
- we use

Save the results under data/distr_n-prep-n_lemma-decade_rsc.txt in your course directory
Result of the download: distr_n-prep-n_lemma-decade_rsc.txt
| <> | >> Next: Tutorial Manipulating Data Sets >> |
Bibliography
Bartsch, Sabine. 2004. Structural and Functional Properties of Collocations in English. A Corpus Study of Lexical and Pragmatic Constraints on Lexical Co-Occurence. Tübingen: Narr.
Wickham, Hadley. 2014. “Tidy Data.” Journal of Statistical Software 59 (10): 1–23.