Data Analysis: Creating the sample data
The sample data set for analysis has been extracted from the Brown family corpora (including BROWN, FROWN, BLOB, FLOB, LOB) using CQPweb.
See Download query results in a TAB-deliminated format for more detailed information on how to extract data sets from CQPweb.
Data set
Full verbs and their parts-of-speech across registers and subcorpora in the Brown family
- Query:
[pos="VV.*"]
- Download:
Download query as plain-text tabulation
- Attributes:
lemmaof verb,posof verb,text_reg(register)text_sc(subcorpus: BROWN, FROWN, BLOB, FLOB, LOB)
- Output options: simple tabulate output

The results should look like this: sample data set
Add meta data information to the data set. We will use metadata listed in two files
d <- read.table("data/distr_vfull_lemma-pos-reg-sc_brownfam.txt",header=F,sep="\t",row.names = NULL,quote="")
colnames(d) <- c("verb","pos","register","corpus")
d.meta <- read.table("data/brown_family_meta.txt",sep="\t",header=T,row.names = NULL,quote="")
d.reg.meta <- read.table("data/brown_family_register_meta.txt",sep="\t",header=T,row.names = NULL,quote="")
d <- merge(d,d.meta)
d <- merge(d,d.reg.meta)write.table(d,file = "data/distr_vfull_lemma-pos-reg-sc_brownfam-meta.txt",quote=FALSE,sep="\t",row.names = FALSE,col.names = T)Data set with subcorpus sizes
- Query:
[] - Download:
Download query as plain-text tabulation - Attributes:
text_reg,text_sc - Output option:
sort and group output
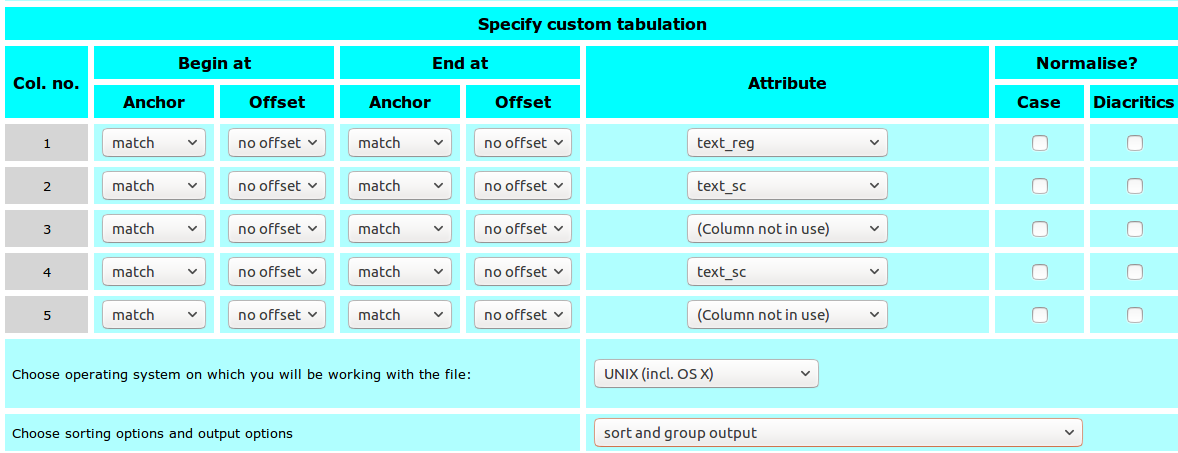
The result should look like this: sample data set with subcorpus frequencies (register and corpora)
We will add the meta data to the subcorpus size file as well.
d <- read.table("data/brown_family_csizes.txt",header=F,sep="\t",row.names = NULL,quote="")
colnames(d) <- c("N","register","corpus")
d.meta <- read.table("data/brown_family_meta.txt",sep="\t",header=T,row.names = NULL,quote="")
d.reg.meta <- read.table("data/brown_family_register_meta.txt",sep="\t",header=T,row.names = NULL,quote="")
d <- merge(d,d.meta)
d <- merge(d,d.reg.meta)
write.table(d,file = "data/brown_family_csizes-meta.txt",quote=FALSE,sep="\t",row.names = FALSE,col.names = T)