


GECCo Corpus
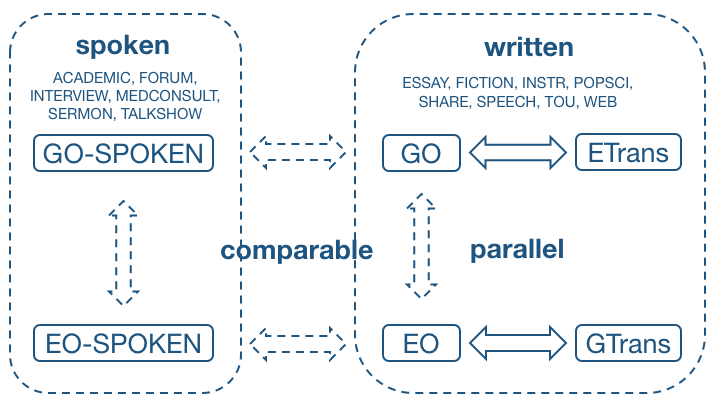
The GECCo (German-English Contrasts in Cohesion) Corpus offers a continuum of different text types (registers) from written to spoken discourse. More precisely, it includes English and German texts of 14 registers, eight of which represent written discourse and the remaining six represent spoken discoure.
The whole number of words contained in the corpus comprise ca. 1,4 Mio. The corpus is pre-annotated on several levels, which include information on tokens, lemmas, morpho-syntactic features (e.g. case, number, etc.), parts-of-speech, pharse chunks and their grammatical functions, as well as and sentence boundaries. The annotation of the written part was partly imported from CroCo (Hansen-Schirra et al., 2012), whereas for the spoken part, we use Stanford POS Tagger (Toutanova et al., 2003) and the Stanford Parser (Klein and Manning, 2003). This corpus is also annotated for the information on cohesion (devices and relations), including coreference, conjunctive relations, substitution, ellipsis and lexical cohesion. The semi-automatic procedures were described in Lapshinova and Kunz (2014). The annotation of ellipsis is manual and the scheme is described in Menzel (2014). The corpus is encoded in the CWB format (CWB, 2010) and can be queried with Corpus Query Processor (CQP) (Evert, 2005).
Written registers1 are: fictional texts (FICTION), political essays (ESSAY), instruction manuals (INSTR), popular-scientific texts (POPSCI), letters to shareholders (SHARE), prepared political speeches (SPEECH), tourism leaflets (TOU), and corporate websites (WEB).
Spoken registers are: academic lectures (ACADEMIC), internet forum excerpts (FORUM), interviews (INTERVIEW), medical consultation interactions (MEDCONSULT), sermons (SERMON), and TV talkshow excerpts (TALKSHOW).
A detailed description of the acquisition and processing of INTERVIEW and academic can be found in Lapshinova-Koltunski et al. (2012).
This part was imported from the existing corpus CroCo described in (Hansen-Schirra et al., 2012).↩
Impressum

Corpus by AuthorName and ContributorName is licensed under a Creative Commons Attribution 4.0 International License.